Turbocharge your tokenization by exploiting parallelism¶
Parallelize Hugging Face Tokenizers with num_proc¶
Processing large datasets can be time-consuming, especially when it comes to tokenizing text.
But what if you could reduce your tokenization time from hours to mere minutes? Without any extra effort? 🤯
In this blog post, we'll show you how to parallelize your tokenization using Hugging Face's num_proc parameter.
Hugging Face Tokenizers¶
Hugging Face, "the AI community building the future", offers a library called transformers, which provides state-of-the-art models and tokenizers for various ML tasks.
Tip
If you're not familiar with Hugging Face, we highly recommend you check it out!
Tokenization is the process of converting text into smaller units (aka tokens), such as words or subwords, that can be more easily processed by NLP models.
It's an essential step in preparing your data for tasks like text classification, sentiment analysis, and machine translation.
The power of parallelization¶
Parallelization is the technique of dividing a computational task into smaller subtasks that can be executed concurrently by multiple processors or cores.
By breaking down the workload and distributing it among several processing units, parallelization can significantly speed up the execution of tasks, including tokenization.
Thanks to its Rust implementation, Hugging Face's tokenizers are already blazingly fast. But what if you could make them even faster? 🚀
Using num_proc for parallelization¶
Hugging Face tokenizers support a num_proc parameter that allows you to parallelize the tokenization process.
By specifying the number of processes to run concurrently, you can take full advantage of your available processing power. Nowadays, most computers have multiple cores, so you can easily speed up your tokenization by using all of them.
Note
You don't have to run on a beefy server to benefit from parallelization. Even a laptop with 4-8 cores can benefit from parallelization.
Here's a code snippet illustrating how to use the num_proc parameter:
import multiprocessing
from datasets import load_dataset
from transformers import AutoTokenizer
# Load any hugging face dataset
data = load_dataset("imdb")
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
# Find your available cores
num_cores = multiprocessing.cpu_count()
# Preprocess your data
train_data = data["train"].shuffle().map(lambda sample: tokenizer(sample["text"]), num_proc=num_cores)
test_data = data["test"].map(lambda sample: tokenizer(sample["text"]), num_proc=num_cores)
If you don't want to use all your available cores, you can specify a lower number or even limit the number of cores to a specific range.
# Use only 8 cores maximum
num_cores = min(8, multiprocessing.cpu_count())
# Use all cores except the last one
num_cores = multiprocessing.cpu_count() - 1
Tip
The lambda function is used to apply the tokenizer to each sample in the dataset. You can define your own function and pass it to the map method instead. It's totally dependent on your use case and the task you're trying to accomplish.
Time to parallelize!¶
It seems like a small change, but parallelization can make a huge difference in your tokenization time.
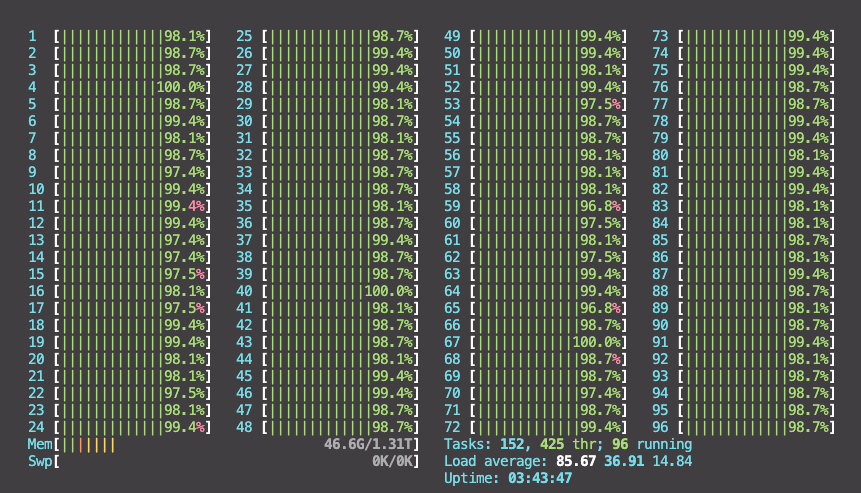
For example, I had to process a 40GB dataset with over 6 million samples. It takes about 4 hours to tokenize it with a single core, but less than 5 minutes with 96 cores!
I know, you're probably thinking "that's great, but I don't have 96 cores" 😅. You're right, but you can still benefit from parallelization, because most computers have at least 8-16 cores nowadays. And spending 20-30 minutes to tokenize a dataset is still a huge improvement compared to 4 hours.
Parallelizing tokenization tasks with Hugging Face's num_proc parameter can yield impressive results, drastically reducing the time it takes to process large datasets.
By taking advantage of parallelization, you can accelerate your natural language processing tasks and focus on what matters most: analyzing and interpreting your data.
Don't forget to share captivating images of parallel processing in action! 🤓 Tweet your parallelization at @chainyo_ai and let me know how much time you saved!